SEOの世界で言われる「インデックス登録」とは、一言で言うと**「Googleという巨大な図書館の本棚に、あなたのサイトが並ぶこと」**を指します。
サイトを作っただけでは、世界中の誰にも見つけてもらえません。Googleのデータベースに登録されて初めて、誰かが検索したときに結果として表示される資格を得られます。
プロの視点で、その仕組みと「具体的にどういう状態か」を詳しく解説します。
前提知識:プロが意識する「クロール」と「インデックス」の違い
確認作業に入る前に、この2つの違いを明確にしておくことが最も重要です。混同すると、問題の原因を見誤ります。
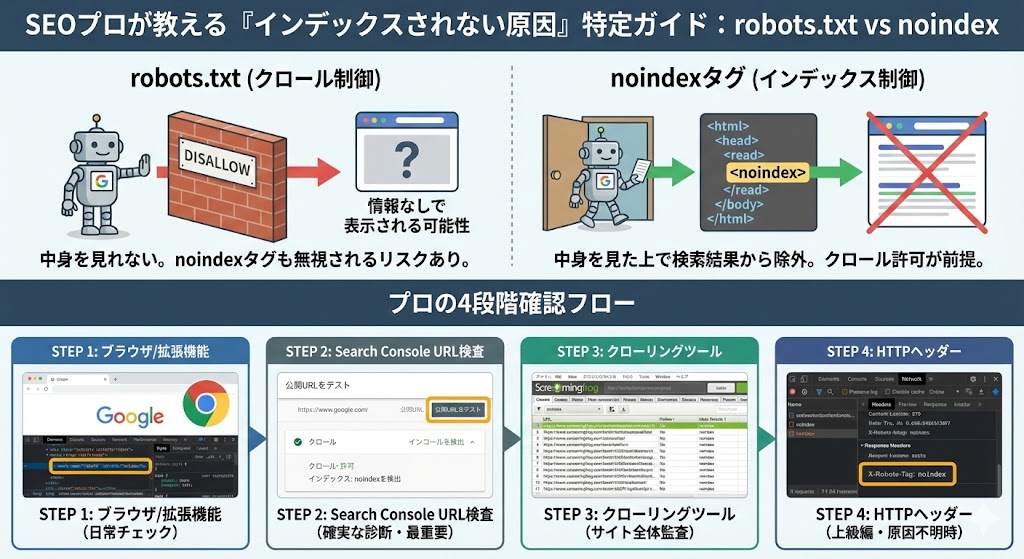
- robots.txt (クロール制御)
- 役割: 「Googlebotさん、この部屋(ページ)には入ってはいけません」という指示。
- 結果: ブロックされると、Googleは中身を見ることができません。
- 注意点: 中身を見れないため、ページ内に
noindexタグが書いてあっても、Googleはそれに気づけません。その結果、「中身は不明だが、リンクが存在する」という状態で、検索結果に不完全な形で表示され続けるリスクがあります。
- noindex タグ (インデックス制御)
- 役割: 「Googlebotさん、部屋に入って中を見てもいいですが、検索結果(電話帳)には載せないでください」という指示。
- 結果: Googleは中身を理解した上で、検索結果から意図的に除外します。
- 条件: この指示をGoogleに読ませるためには、robots.txtでクロールを許可している必要があります。
実践:プロが行う4段階の確認ステップ
フェーズ1:【単一ページ】ブラウザでの迅速チェック(目視)
まずは手元のブラウザで対象のページを開き、HTML内に記述があるかを確認します。
方法A:デベロッパーツール(検証モード)を使う【推奨】 ソースコードを表示(右クリック→「ページのソースを表示」)するだけでは、JavaScriptで動的に挿入されたタグを見落とす可能性があります。プロはデベロッパーツールを使います。
- Chromeなどで対象ページを開き、
F12キーを押してデベロッパーツールを開きます。 - 「Elements」(要素)タブを選択します。
Ctrl + F(MacはCmd + F) で検索窓を開き、noindexと入力します。<head>タグ内に以下の記述が見つかれば、インデックス拒否が設定されています。
<meta name="robots" content="noindex">
<meta name="googlebot" content="noindex">
方法B:SEO拡張機能を使う【最速】 プロは作業効率化のため、ブラウザ拡張機能(例:SEO Pro Extension, Detailed SEO Extension, Ahrefs SEO Toolbarなど)を常用します。これらを使えば、ワンクリックでそのページの「Robots Tag」情報が表示されるため、一瞬で判断できます。
フェーズ2:【単一ページ】「正解」を確認する(Google Search Console)
ブラウザ上の表示がどうであれ、**「Googleが現在そのページをどう認識しているか」**の正解はGoogle Search Console(GSC)にしかありません。これが最も確実な方法です。
手順:URL検査ツールを使用する
- GSC(Google Search Console)を開き、画面上部の検索窓に対象ページのURLを入力してEnterキーを押します。
- 結果画面が表示されたら、右上の**「公開URLをテスト」**をクリックします。(※ここが重要!現在の最新状態を確認するためです)
- テスト結果の「ページの可用性」セクションを確認します。
▼ プロがチェックするポイント ▼
- 【クロールの許可】robots.txt の確認
- 「クロール」の項目を見ます。
許可されていますとなっていればOK。いいえ: robots.txt によってブロックされましたとなっている場合、Googleはページの中に入れません。この状態では noindex の有無を正確に判定できません。 まずはrobots.txtを修正する必要があります。
- 【インデックスの許可】noindexタグ の確認
- クロールが許可されている前提で、「インデックス登録」の項目を見ます。
許可されていますとなっていれば、noindexタグは入っていません。いいえ: 'noindex' が検出されましたとなっていれば、noindexタグが有効に機能しています。
フェーズ3:【サイト全体】クローリングツールでの一括チェック
サイトのページ数が多い場合、1ページずつGSCで検査するのは非現実的です。プロはクローリングツール(Screaming Frog SEO Spiderなど)を使ってサイト全体をスキャンします。
手順(Screaming Frogの例):
- ツールに対象サイトのURLを入力し、クロールを開始します。
- クロール完了後、「Directives(指示)」タブを開きます。
- フィルターで「Noindex」を選択します。
Meta Robots 1またはX-Robots-Tag 1の列にnoindexと表示されているページの一覧が抽出されます。
プロの視点: これで、「意図せずnoindexになっている重要なページはないか?」「逆に、noindexにすべきページ(低品質なページ、重複ページなど)に設定が漏れていないか?」を俯瞰して分析します。
フェーズ4:【上級編】HTTPヘッダー(X-Robots-Tag)の確認
noindex は、HTMLの <head> 内だけでなく、サーバーからのレスポンスヘッダー(HTTPヘッダー)で指定することも可能です。これを X-Robots-Tag と呼びます。
HTMLソースを見ても meta name="robots" がないのに、GSCで「noindexが検出されました」と出る場合は、これが原因です。PDFファイルなどをインデックス拒否する場合によく使われます。
確認方法:
- Chromeのデベロッパーツールを開き(F12)、「Network」(ネットワーク)タブを選択します。
- ページをリロードします。
- 一番上のリクエスト(通常はページ自体のHTML)をクリックします。
- 右側に表示される「Headers」タブの中の「Response Headers」を確認します。
- ここに以下の記述があれば、noindexが効いています。
HTTP
X-Robots-Tag: noindex
まとめ:プロの確認フロー
- 【日常的な確認】 ブラウザ拡張機能でサッと見る。
- 【確実な診断】 Google Search Consoleの「公開URLテスト」で、robots.txtのブロック状況と併せて確認する。(これが最も重要)
- 【サイト全体の監査】 Screaming Frog等のツールで、意図しない設定漏れを一括チェックする。
- 【原因不明時】 HTTPヘッダーの
X-Robots-Tagも疑う。

